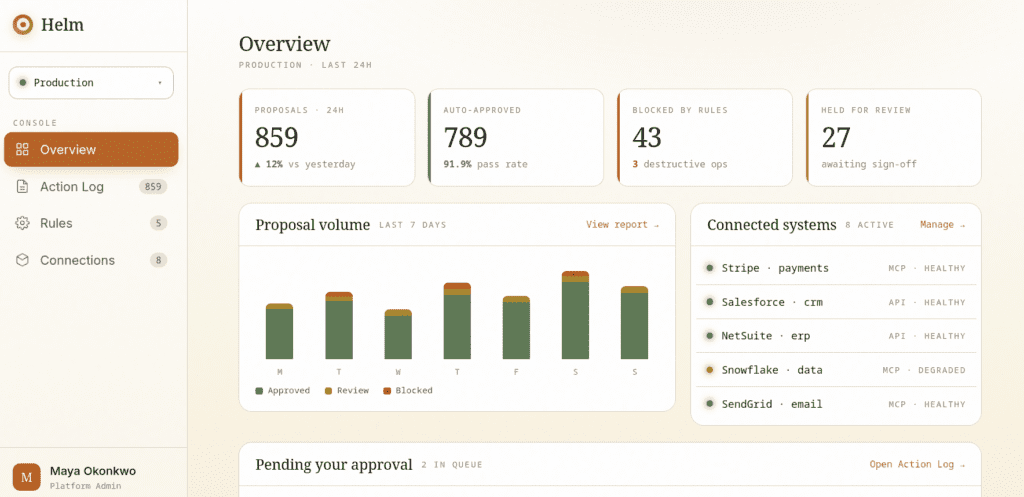
Governing MCP Tool Calls: Why AI Agents Need a Control Layer Before They Touch Production
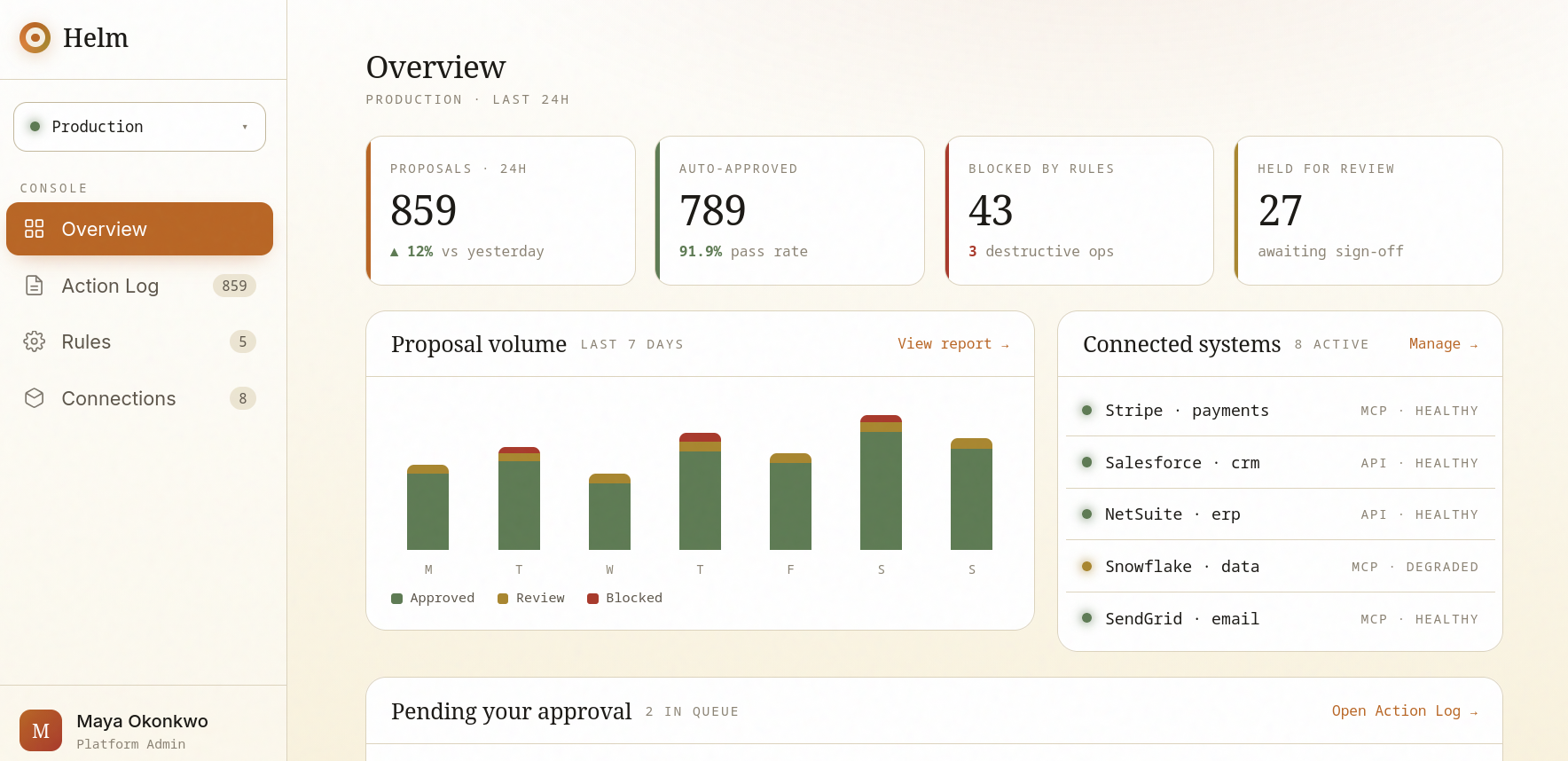
A year ago, “AI risk” mostly meant a chatbot saying something embarrassing. The worst case was reputational. Today, the same models are wired into Stripe, Salesforce, NetSuite, and internal APIs through the Model Context Protocol (MCP), and the worst case is a $90,000 vendor onboarded by mistake, 12,800 customer records deleted, or a refund issued outside policy — executed in milliseconds, with no one in the loop.
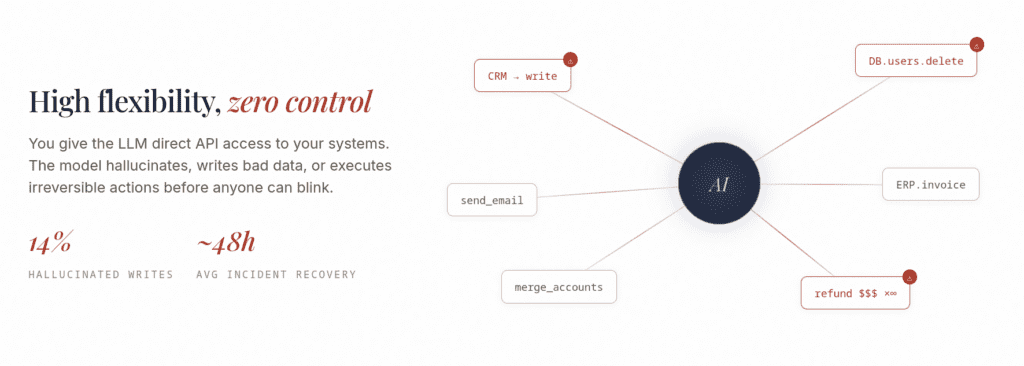
The shift is simple but consequential: agents no longer just produce text. They take actions. And MCP, the standard that makes those actions possible, was designed to connect agents to tools — not to govern what those agents are allowed to do once connected.
This is the gap that an execution control layer fills. Below is what the gap actually is, why MCP doesn’t close it on its own, and how to think about the tools — including Helm — that do.
What MCP gives you, and what it deliberately leaves out
MCP is an open standard for connecting AI agents to external tools, data sources, and systems. It standardizes how an agent discovers a tool and invokes it. That standardization is the reason the agentic ecosystem has moved so fast: build one MCP server for your payments system, and any compliant agent can call it.
What MCP does not define is enforcement. The protocol describes the conversation between an agent and a tool; it does not, on its own, require strong authentication, scoped permissions, or an audit trail of every call. Security agencies have started saying so explicitly — U.S. intelligence guidance issued earlier this year flagged MCP as an active enterprise risk rather than a theoretical one, noting that production deployments in finance and legal had outpaced the controls now considered baseline.
So when an agent decides to call payments.refund or crm.delete, three uncomfortable properties show up at once:
- The agent’s reasoning can be wrong or manipulated. Industry write-ups consistently point to prompt injection as the headline MCP threat: an agent that summarizes a document, routes an email, or reads a web page can be fed hidden instructions, and it cannot reliably tell data from commands. It then executes those instructions using its own credentials.
- The action is often irreversible. A refund clears. A record is gone. A vendor is live in the ERP. Unlike a bad sentence, a bad write doesn’t get retracted by hitting “regenerate.”
- There may be no record of why it happened. Without a logging layer, you get the outcome but not the chain — the proposal, the rule that allowed it, the data the agent read, and the source it came from.
None of this is a flaw in MCP. It’s a scope decision. MCP moves the action; governing the action is a separate job.
“Just a JSON API” is the dangerous mental model
The most common mistake teams make is treating an MCP call like any other backend integration — a JSON request that either succeeds or fails. That framing misses what’s new.
A traditional integration is called by your code, on a path you wrote, after conditions you checked. An MCP call is initiated by a probabilistic model that can chain tools in combinations no one anticipated, in response to inputs no one reviewed. The autonomy is the point — and it’s also what removes the human checkpoint that used to sit between “decision” and “execution.”
That’s why the answer isn’t “review the model’s outputs more carefully.” By the time a destructive call is an output, it’s already on its way to production. The control has to live between the agent’s proposal and the system’s execution.
What a control layer actually has to do
If you strip the category down to its job, a control layer for agentic AI needs to do four things on every action an agent proposes:
- Force a proposal, not a raw write. The agent should return a structured statement of intent — what it wants to do and why — rather than firing directly at your system. This single architectural choice turns an opaque action into something you can inspect.
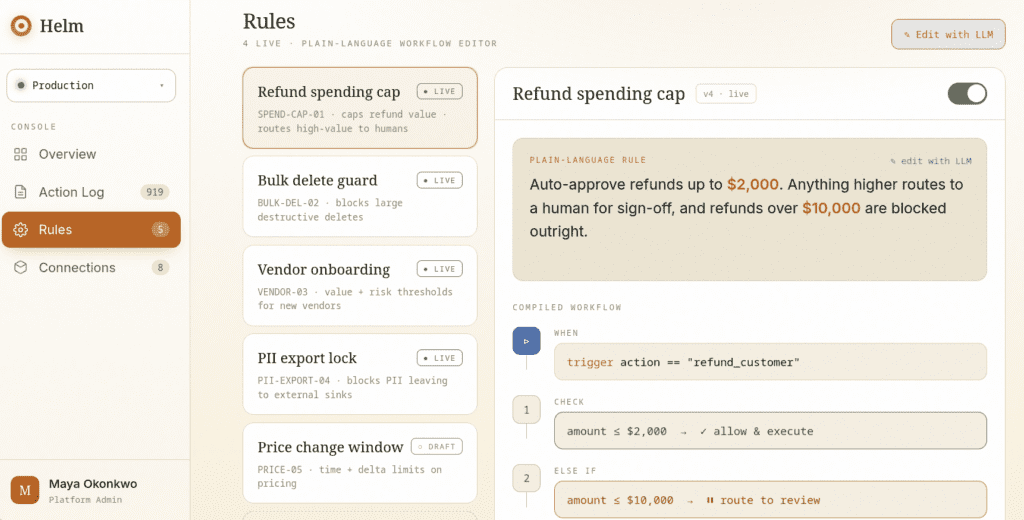
- Gate it against deterministic rules. A spending cap, a destructive-operation threshold, an approval requirement over a dollar amount — evaluated in code, not by another model. Determinism is what makes the boundary trustworthy: the same proposal gets the same verdict every time.
- Log it end to end. Every approved or blocked call recorded and traceable back through the rule that judged it, the proposal, and the underlying data — the difference between a forensic record and an actual control.
- Make it reversible. High-stakes actions route to a human; low-stakes actions flow through automatically; and when something does slip, there’s a one-click undo rather than database surgery at 2 a.m.
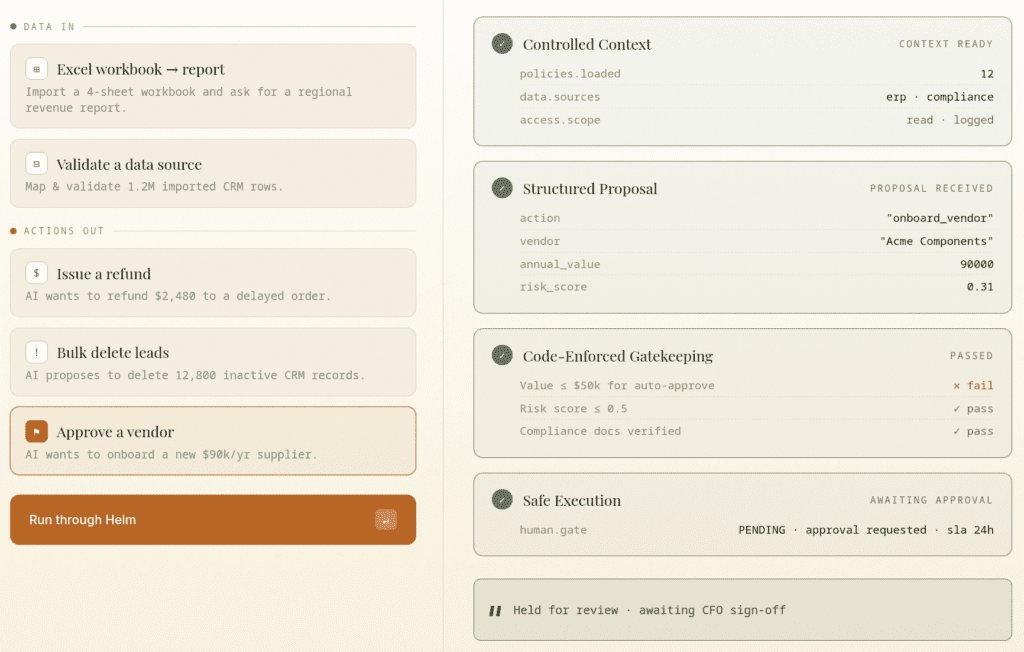
The order matters. Logging without enforcement is just observability after the fact. Enforcement without reversibility leaves you with a clean record of an unfixable mistake.
The tool landscape — and where each piece fits
“Controlling AI agents” has become a crowded phrase, but the tools under it are solving genuinely different parts of the problem. It helps to separate them into three layers, because most teams will end up using more than one.
MCP gateways and registries: securing who can call what
A growing set of tools put a gateway in front of your MCP servers to handle identity, access control, and inventory. TrueFoundry’s MCP Gateway centralizes tool registration, injects per-user identity through your existing SSO, vaults credentials, and keeps SOC 2 audit trails — deployed inside your own cloud so data doesn’t leave your network. Enkrypt AI focuses on scanning MCP servers for vulnerabilities, curating an approved registry, and enforcing policy at runtime. Cloudflare has published a reference architecture for running MCP at scale with centralized governance and authentication through Cloudflare Access. Obot AI and others play in the same registry-and-access space.
These tools answer a critical question: which agents and users are allowed to reach which tools, with which credentials. That’s necessary. It is not the same as deciding whether a specific proposed action — this refund, this deletion, this purchase — should be allowed to execute given your business rules, and whether you can undo it afterward.
Observability: telling you what happened
LangSmith, Langfuse, and Helicone trace agent runs, capture token usage, and help you debug behavior. They are excellent at visibility. But observability is, by definition, a record of what already occurred. It tells you a bad write happened; it doesn’t stop the write, and it doesn’t give you an undo path.
Text guardrails: filtering what the model says
NVIDIA NeMo Guardrails and Guardrails AI constrain model inputs and outputs — blocking unsafe content, enforcing formats, catching some injection patterns at the text layer. Valuable for content safety. But the business risk in an agentic system usually isn’t a sentence; it’s a dollar amount, a contract, or a customer record. Filtering text doesn’t govern the API or MCP call that moves the money.
Execution control: governing whether the action runs — and whether you can reverse it
This is the layer Helm occupies, and it’s deliberately a different job from the three above. Helm sits between your agents and your systems and runs the same four steps on every MCP or API call:
- The agent returns a structured JSON proposal, never a raw write.
- Helm checks it against deterministic rules you edit and audit like a workflow — in plain language, versioned and diffed, no redeploy to change a threshold.
- Every call is logged end to end, traceable from verdict back to the source record.
- High-risk actions hit human-in-the-loop gates, and every executed action keeps a one-click undo path because the original is always preserved.
In practice the layers are complementary, not competitive. A gateway can secure who connects; observability can show you what the agents did; Helm decides whether this specific action should execute, records why, and lets you reverse it. A serious production deployment often wants more than one of these — the mistake is assuming any single one covers the others.
A short checklist before you put an agent into production
If you’re evaluating how to govern agentic actions — with Helm or anything else — these are the questions that separate real control from a dashboard:
- Does the agent submit a proposal that can be inspected, or does it write directly to the system?
- Are rules enforced in deterministic code, or by another model that can also be wrong?
- Can you trace any action back to the rule, the proposal, and the source data?
- Is there a literal undo for an action that’s already executed?
- Can a non-engineer change a policy without a multi-week pull-request cycle?
- Do high-risk actions wait for a human while routine ones flow through?
If the answer to several of these is “no,” the agent isn’t really in production safely — it’s in production on borrowed time.
The bottom line
MCP solved connection. It did not solve control, and it was never meant to. As agents move from drafting text to issuing refunds, onboarding vendors, and deleting records, the decisive layer is the one that sits between the agent’s proposal and your system’s execution — gating it against rules you can audit, logging it so you can trace it, and keeping a way to reverse it when something goes wrong.
That’s the layer Helm was built to be: AI proposes, your code executes, Helm controls. If you’re wiring agents into systems where a wrong action costs real money or real trust, book a technical walkthrough and see it run against your own scenarios.
Helm is the control and audit layer for agentic AI from Consuly. It gates, logs, and makes reversible every API and MCP call before it touches a real system — SOC 2 Type II, GDPR, and EU AI Act ready.


