ETL is Dead. Long Live Semantic ETL: Why Traditional Pipelines Can’t Feed an AI Stack
TL;DR: The ETL category was built in the 1990s to feed BI dashboards. It assumes rigid schemas, batch windows, and a destination that doesn’t care about meaning — just rows. Modern AI stacks invert every one of those assumptions. They need transformation that understands a test record versus a real one, normalizes against international standards (ISO 4217, ISO 8601) by default, reconciles every input row one-to-one with the output, and emits AI-ready records — not just rows in a warehouse. This new category is Semantic ETL, and ContentAtlas is the product we built around it.
The Category is Cracking in Public
You don’t need a think piece to know the legacy ETL category is in trouble — the calendar is doing the work. Informatica PowerCenter 10.5, the platform that has anchored enterprise data integration for two decades, reaches end of standard support on March 31, 2026. Informatica itself is no longer independent: Salesforce closed its $8 billion acquisition on November 18, 2025, folding catalog, MDM, and integration into the Salesforce platform expressly to build a “data foundation for agentic AI.” Talend is now a Qlik product. SSIS hasn’t had a meaningful architectural update in a decade.
This isn’t a story about three vendors. It’s a story about a category that was designed for a problem that has moved.
What Traditional ETL Was Actually Designed For
Strip away the marketing and the classical ETL stack — Informatica PowerCenter, Talend, SSIS, the older Alteryx workflows — was optimized for one shape of problem:
- Known sources, known targets. A handful of operational systems (ERP, CRM, billing) feeding a star-schema warehouse.
- Batch windows. Nightly or hourly runs into a destination that would be queried by humans the next morning.
- Schema-first, meaning-blind. The tool moves a value from column A to column B. Whether that value is meaningful — or even real — is somebody else’s problem.
- Dashboard as the consumer. The end user is a BI tool. BI tools tolerate a lot. A missing field renders as a blank cell. A weird date format gets a custom formatter. A duplicate is a footnote.
That stack worked, because the destination — a human looking at a chart — could pattern-match around the noise.
The Consumer Changed. The Tools Didn’t.
The new destination is an LLM, a retrieval index, or an agent. None of these tolerate what BI tolerated.
Industry analysis in 2026 is converging on the same uncomfortable number: when production RAG fails, the failure point is retrieval roughly 73% of the time, not generation. The model isn’t the problem. The data going into the model is. And the data going into the model came out of an ETL pipeline that was never asked to understand what it was moving.
VentureBeat’s Q1 2026 Pulse data tells the same story from the buyer side: enterprise intent to adopt hybrid retrieval tripled from 10.3% to 33.3% in a single quarter, as organizations that went wide on RAG in 2025 hit the same wall: the architecture works in the demo and degrades silently in production. Quietly, the budget is moving from “add another retrieval layer” to “fix the data we’re feeding it.”
That fix doesn’t live in the vector database. It lives upstream, in the transformation layer — the layer that traditional ETL owns and is structurally unequipped to deliver on.
Five Structural Reasons Legacy ETL Can’t Feed an AI Stack
These are not bugs in any specific product. They are the shape of a category that was designed for a different consumer.
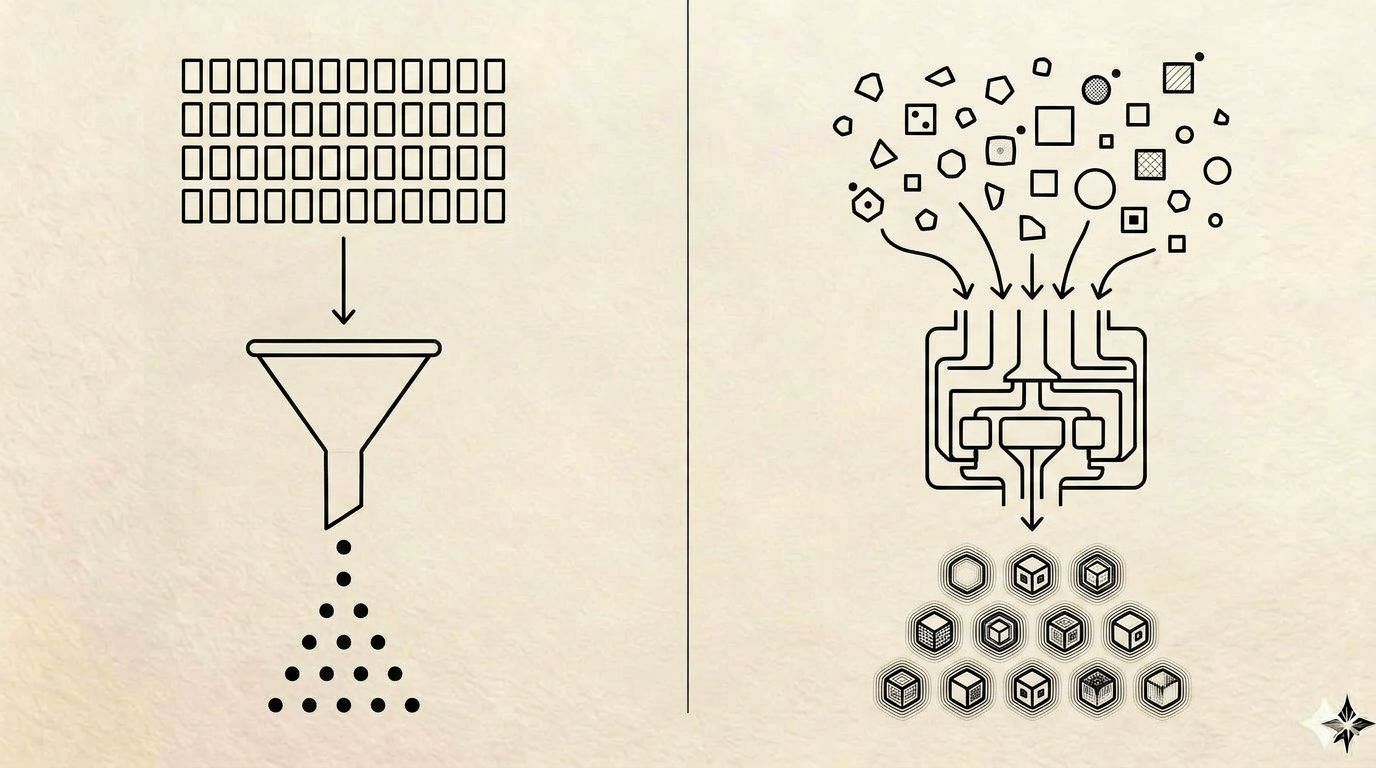
1. It moves values, not meaning. A traditional ETL job sees a string in a customer_name column and copies it to a destination column. It does not know that "TEST TEST", "asdf", "do not use", and "Acme Corp (TEMP)" are not real customers. When that data lands in a RAG index, the model retrieves them as confidently as any other record. The hallucination wasn’t the model’s fault. The retrieval was perfectly accurate. The meaning was wrong, and nothing in the pipeline ever checked.
2. It is schema-rigid where AI consumers are format-fluid. Legacy ETL requires you to declare a single target schema before you run. This is fine for a warehouse. It is the wrong model for a stack where the same source needs to feed a warehouse, a vector index, an agent tool call, and a JSON document store — each with a different idea of what a “field” is. You end up running three or four parallel pipelines that all do roughly the same work and drift out of sync.
3. It normalizes inconsistently, if at all. Ask a traditional ETL pipeline whether a JPY value should have decimals (it shouldn’t, per ISO 4217), whether a date string is ISO 8601-compliant, whether an IBAN passes its ISO 13616 checksum, or whether a phone number is dialable in its country code. The answer, in every general-purpose tool, is: only if someone wrote that rule. Custom rules are expensive, undocumented, and the first thing to rot when the engineer who wrote them leaves.
4. It is batch-shaped in a streaming world. Agents don’t wait for the 2am batch. They query when the user asks. A pipeline that lands clean data tomorrow is, for an agent making a decision today, indistinguishable from a pipeline that didn’t run at all.
5. It cannot reconcile what it processed. Ask a traditional ETL pipeline to prove that every one of the 247,318 records that came in was accounted for in the output — mapped, transformed, soft-errored, or hard-errored — and the answer is usually a partial log file, a row count that doesn’t quite tie, and a Slack thread reconstructing what happened. For an AI system feeding regulated decisions, this is not an inconvenience. It is a stop-ship.
The “AI ETL” Trap
The first wave of replacement products is making the problem worse, not better.
A growing number of vendors are marketing “AI-powered ETL” tools where a large language model performs the transformation itself: feed the row in, ask the model to clean it, take whatever comes out. The demos look impressive. In production, the architecture is structurally indefensible.
The output is probabilistic. It varies run to run. It can’t be reconciled. A CFO cannot sign off on a quarterly close that was produced by a non-deterministic process, and a regulator cannot audit one. You have replaced a tool that didn’t understand your data with a tool that hallucinates about your data — and the hallucinations are now part of the source of truth.
This is why we put a hard line through “LLM as ETL” when we defined the new category. The model belongs in the design loop, not the runtime path.
What Semantic ETL Changes
The category that replaces traditional ETL — we’ve written a full definition here — is built on a different architecture. Five properties define it:
- AI as the analyst, system as the executor. The LLM samples source data, reads existing schemas and mappings, ingests user instructions, and proposes the mapping and transformation logic. The actual transformation then runs as deterministic SQL and system operations. Same input, same output, every time. Probabilistic understanding, deterministic execution.
- ISO normalization, built in. ISO 4217 with correct decimal precision per currency code. ISO 8601 for dates. ISO 13616 with checksum for IBAN. ISO 3166 for countries. E.164 for phones. Not features somebody has to write — defaults that ship.
- Meaning-aware validation. The pipeline distinguishes a real record from a non-real one — test data, placeholders, sentinels, deprecated entities — using semantic signals discovered by the AI analyst, then enforced by deterministic rules at runtime.
- One-to-one reconciliation. Every input record is accounted for in one of four states (mapped clean, transformed with flag, soft error, hard error). Counts tie exactly. Like a bank reconciliation. Nothing is silently dropped or rounded away.
- Declarative, portable mappings. Logic lives in version-controlled JSON. It diffs in git. It survives the project. The artifact is the contract between systems, not a 600-line Python script that dies with its author.
If a pipeline ships all five — as defaults, not as things a customer can build on top — it qualifies as Semantic ETL. If any of them is “well, you can build that yourself,” it’s the same architecture that produced the data quality problem in the first place.
Where ContentAtlas Fits — and Where It Deliberately Doesn’t
This is the architecture ContentAtlas was built on. A few things worth being explicit about, because the scope matters.
What ContentAtlas does: database content transformation. It samples your source data, uses the LLM of your choice to propose the mapping (with your own API keys — your data is never exposed to a shared service), runs the transformation deterministically through SQL and system operations, validates against ISO standards by default, flags non-real records, reconciles every input row one-to-one with the output, and emits clean records in whatever format the consumer needs — JSON, XML, SQL, CSV. Mappings export as portable JSON. See how AI Mapping works.
What ContentAtlas does not do: RAG. Indexing. Vector storage. These are downstream consumers of clean data, and they are deliberately somebody else’s job. We made this choice on purpose. A transformation tool that also tries to be a vector database ends up being a mediocre version of both. ContentAtlas produces the AI-ready records; the team building the RAG system, the agent, or the warehouse consumes them.
The clean separation is the point. Semantic ETL is upstream of every AI consumer, not bundled with any one of them.
The Bottom Line
The legacy ETL category isn’t dying because the vendors got lazy. It’s dying because the consumer it was designed for — the BI dashboard — is no longer the consumer that matters. The new consumer is a model that will confidently lie if you feed it badly typed currencies, ambiguous dates, test records, and IBANs nobody validated. And the first wave of replacement tools, the ones that put an LLM in the runtime path, have replaced a meaning-blind pipeline with an unauditable one.
You can keep paying for batch pipelines that move rows. You can bet on a probabilistic ETL tool and hope the auditor doesn’t ask. Or you can move to a transformation layer that understands what it’s moving, runs it deterministically, and reconciles every record one-to-one — so the data the AI sees is data the business can defend.
That’s the shift. That’s Semantic ETL. And it is the category enterprises will be buying into for the rest of this decade.
See how ContentAtlas implements Semantic ETL →
Further reading from Consuly.ai: