The “Million-Token” Myth: Why AI Context Windows Are Shrinking in Practice
In 2026, the AI arms race is defined by a single metric: the context window. With Claude, Gemini, and GPT-5 offering capacities from 200,000 to over a million tokens, the enterprise narrative has been simple: just upload everything. However, production data now tells a different story. For executives, the gap between “advertised capacity” and “usable performance” is no longer a technical nuance—it’s a major driver of hidden costs and operational risk.
The Phenomenon: “Context Rot”
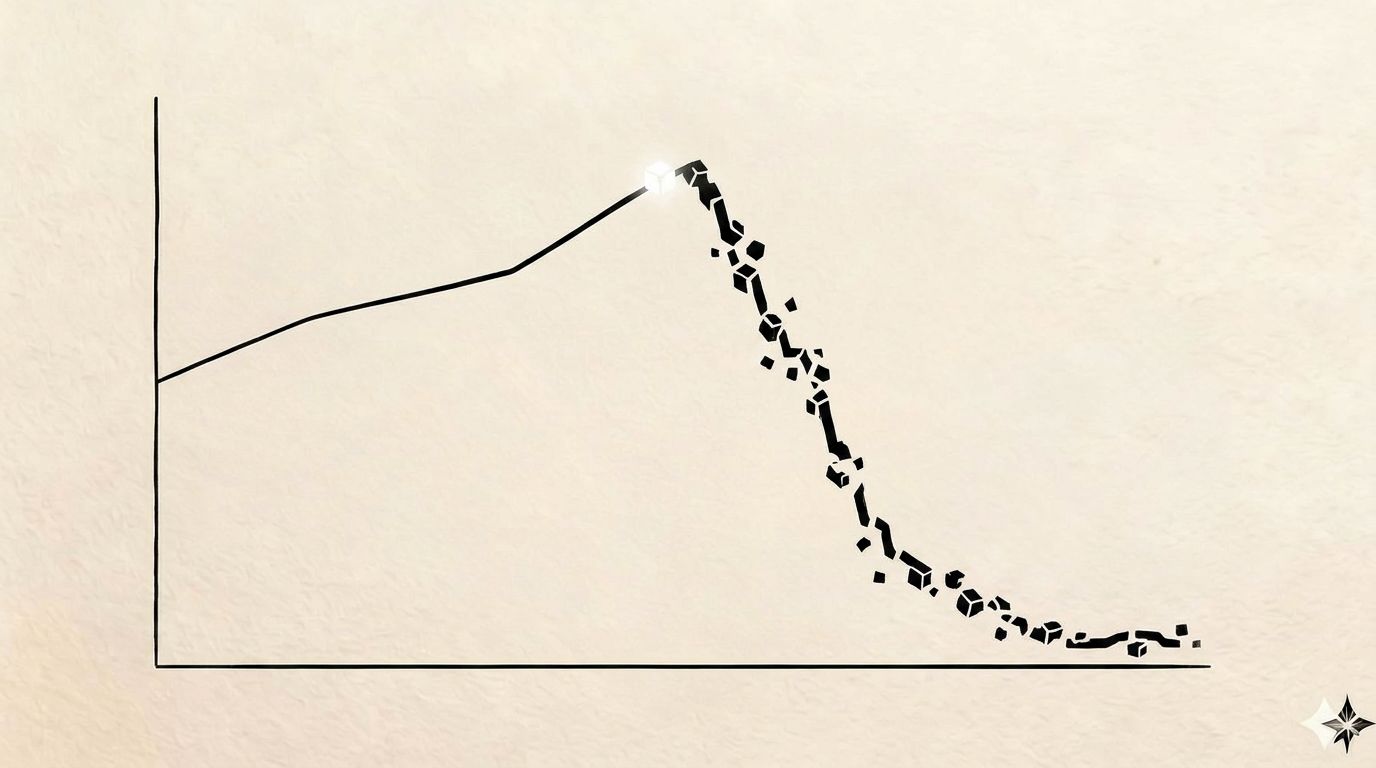
Research from Chroma (Hong et al., 2025) has formally identified Context Rot: a measurable, continuous degradation in model quality as input length increases. Unlike a “hard limit,” this rot begins long before the window is full. A model with a 200,000-token capacity can show significant accuracy drops at just 50,000 tokens.
The failure mode is silent; the AI doesn’t crash, it simply becomes less reliable. It stays confident while its reasoning becomes brittle.
The Hallucination Floor
The most rigorous evaluation to date—the RIKER study (Roig, 2026)—benchmarked 35 models across 172 billion tokens. The findings are a wake-up call for regulated industries:
- Scaling Hallucinations: In document Q&A, fabrication rates for top-tier models nearly tripled when moving from 32K to 128K tokens.
- The 10% Barrier: At 200K tokens, every model tested exceeded a 10% fabrication rate.
- Safety Instability: As context grows, safety guardrails become “unstable,” causing models to either over-refuse harmless tasks or bypass safety protocols entirely.
The Strategic Pivot: Context Engineering
The 2025 thesis that “long context kills RAG” has proven false. Instead, we are seeing a return to Context Engineering. Intelligent retrieval—selecting only the most relevant data to pass to the model—consistently outperforms the “stuff the window” approach on both accuracy and cost.
For decision-makers, “stuffing the window” is a double-hit to the bottom line: you pay premium surcharges (often 2x) for high-token requests while receiving objectively worse output.
Executive Action Plan
- Audit for Length: Identify production prompts exceeding 100,000 tokens. These are your highest-risk areas for silent failures.
- Measure “Usable” Windows: Ignore spec sheets. Benchmark your specific tasks (legal review, code analysis, etc.) to find the “inflection point” where your chosen model starts to rot.
- Invest in Retrieval (RAG): High-performance AI isn’t about who has the biggest window; it’s about who uses the smallest window most effectively.
- Update Governance: If you deploy AI agents, establish “context resets.” Without them, agents lose the plot as their working memory accumulates.
The Bottom Line: In 2026, the competitive advantage isn’t having the biggest model—it’s the engineering discipline to keep your context lean. Reliability is the new scale.