The Agent Maturity Curve: Why LangChain’s Interrupt 2026 Announcements Signal a Shift From Prototypes to Production
In 2026, every enterprise has built an AI agent. Most can’t keep them running. The dirty secret of the agent boom is that the gap between a working demo and a reliable production service is measured in quarters of engineering work, not weeks. This is the gap LangChain just announced it wants to close.
At their Interrupt 2026 conference, LangChain shipped a coordinated set of products across the entire agent lifecycle: Interrupt 2026 Overview. For decision-makers, the announcements are less about features and more about a strategic message: the infrastructure layer for agents is consolidating, and “build it yourself” is becoming the expensive option.
The Real Cost of DIY Agent Infrastructure
Before evaluating what LangChain shipped, it helps to understand what teams are actually paying for today. A production-grade agent stack requires: a tracing and observability layer, a sandboxed code execution environment, durable execution for long-running tasks, a governance layer for spend and PII, and a feedback loop to fix failures.
Most enterprises stitch this together from five to seven vendors plus internal engineering. The total cost of ownership isn’t the license fees—it’s the integration tax, the on-call burden, and the months of latency between identifying a problem and shipping a fix.
LangChain’s bet is that this stack is now mature enough to be productized.
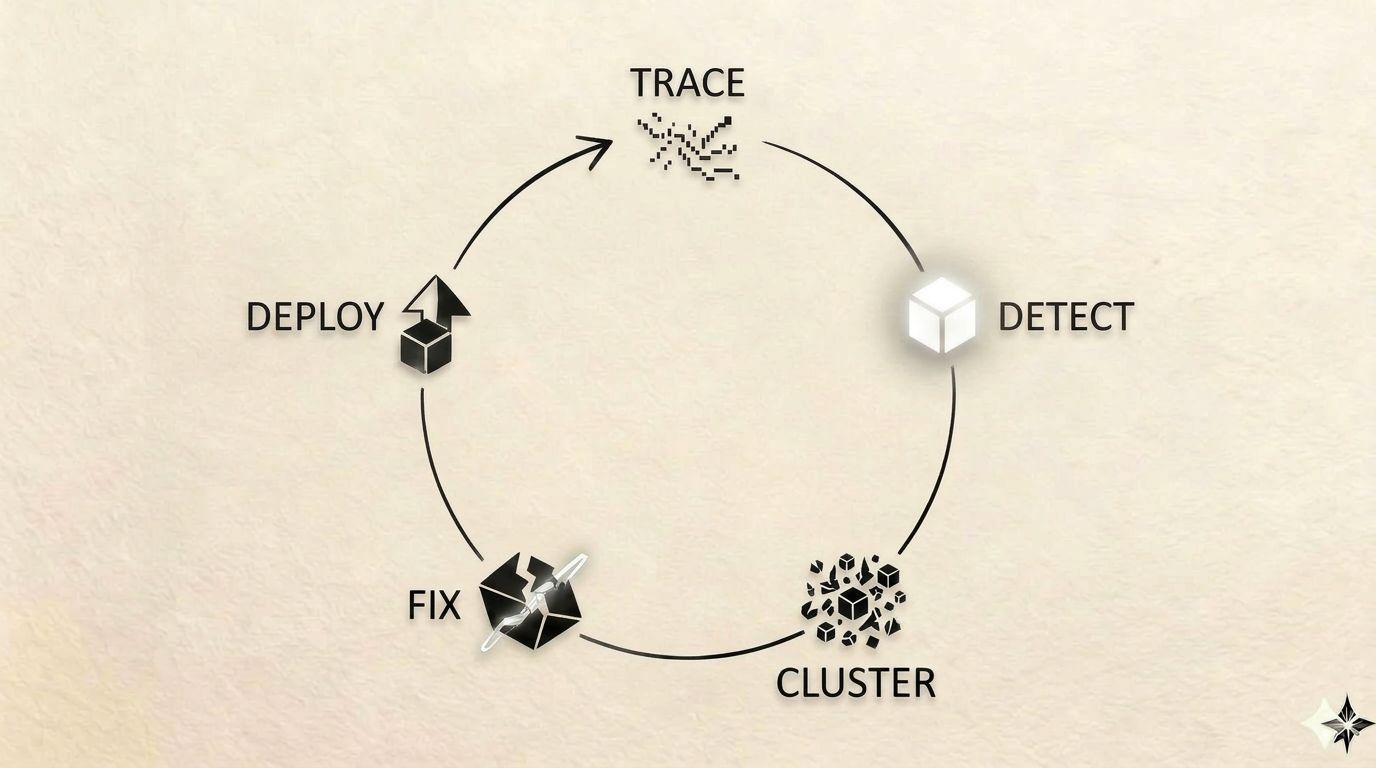
What Actually Shipped — and Why It Matters
LangSmith Engine (Public Beta) — Watches production traces, clusters failures into named issues, and proposes code fixes automatically. Customers like Cogent and Campfire have already used it to resolve issues affecting thousands of traces. The business implication: the feedback loop from “user reports a bug” to “fix is in review” compresses from days to hours.
SmithDB — A purpose-built database for agent observability, delivering up to 15x faster query performance on the deeply nested traces agents generate. This sounds technical, but the ROI is concrete: faster queries mean engineers can actually debug at 3 AM instead of waiting for queries to return. It also signals that general-purpose observability tools (Datadog, New Relic) are not optimized for agent workloads.
Managed Deep Agents (Private Beta) — Hosted infrastructure for the durable execution, memory, and sandboxed code that long-running agents need. This is the “do you really want to run your own Kubernetes for agents?” question, answered.
LangSmith Sandboxes (GA) — Isolated microVMs for safe agent code execution. Production-ready, with snapshotting and an auth proxy that keeps secrets out of the runtime. For regulated industries, this is the difference between “agents can write code” and “agents can write code without violating SOC 2.”
LLM Gateway (Private Beta) — Enforces hard spend caps at the organization, workspace, or API key level and redacts PII before requests leave the environment. This is the single most important governance feature for any enterprise scaling beyond pilots.
Context Hub — Versioned, collaborative control over the AGENTS.md files, skills, and policies your agents follow. Essentially Git for agent instructions.
The Strategic Read
Three signals stand out for business leaders:
1. The agent stack is consolidating. Two years ago, the question was “which framework do we use?” Today, the question is “which platform do we standardize on?” LangChain is making the case that observability, deployment, governance, and improvement are not separate buying decisions.
2. Autonomous improvement is becoming table stakes. Engine is the most strategically important announcement because it changes the economics of agent maintenance. If failures cluster and fix themselves, the marginal cost of operating ten agents approaches the cost of operating one. That is the unlock for genuine scale.
3. Governance ships with the platform, not after it. LLM Gateway and Context Hub are not afterthoughts. The vendors who win enterprise budgets in 2026 are the ones who answer the compliance question on day one, not after a six-month security review.
Executive Action Plan
- Audit your current agent stack. Count the vendors and internal services in your production pipeline. If the answer is more than five, you have an integration tax problem worth quantifying.
- Measure your “trace to fix” latency. How long does it take your team to go from a user-reported issue to a deployed fix? If it’s measured in days, autonomous failure clustering changes your operating model.
- Get the governance layer in front of the agents, not behind them. Spend caps, PII redaction, and audit logs are not optional at scale. Verify your current stack enforces them before requests leave your environment, not after.
- Re-evaluate the build-vs-buy question on observability. General-purpose APM tools were not designed for traces with megabytes of nested spans. If your team is spending engineering cycles making Datadog work for agents, that’s a signal worth acting on.
The Bottom Line
The story of 2025 was building agents. The story of 2026 is operating them. The competitive advantage is no longer who can prototype the most impressive demo—it’s who can run fifty agents in production reliably, governed, and improving on their own. LangChain just made an aggressive bid to own that layer. Whether or not they’re the right partner for your stack, the questions they’re forcing you to ask are the right ones.
Reliability is the new scale. And in 2026, reliability is bought, not built.


